The Ultimate Guide to Web Scraping in 2024: Framework, Tools & Techniques
Take a deep dive into our CCCD framework to learn the best web scraping techniques and practices of 2024. In today’s data-driven world, accessing up-to-date

Uri Knorovich

The Ultimate Guide to Web Scraping in 2024: Framework, Tools & Techniques
Take a deep dive into our CCCD framework to learn the best web scraping techniques and practices of 2024. In today’s data-driven world, accessing up-to-date
Uri Knorovich
Most popular articles

Get structured, reliable data for your stack.
Take a deep dive into our CCCD framework to learn the best web scraping techniques and practices of 2024.
In today’s data-driven world, accessing up-to-date and relevant information is vital for making informed decisions, optimizing operations, staying competitive, managing risks, and advancing AI models. Web scraping is a powerful method to gather critical data efficiently from a multitude of online sources.
Recent research by Piotr Śpiewanowski highlights the significant capabilities of web scraping in expanding and improving the efficiency of data collection. For example, while the U.S. Bureau of Labor Statistics processes around 80,000 price entries monthly, The Billion Prices Project, a large-scale data-scraping project made by MIT, used to capture half a million price quotes daily in the U.S. alone. The evolution of web scraping, driven by advancements in AI, browser fingerprinting, and residential proxies, underscores its adaptability to emerging challenges and requirements.
This guide aims to assist both novice and seasoned web scrapers in navigating this rapidly evolving field. We introduce the Crawl, Collect, Clean, & Debug (CCCD) framework—a structured approach to evaluating and optimizing web scraping setups—and explore leading tools and strategies for each phase.
For a deeper dive, check out our additional resources:
- Part 2: Crawling and Data Collection in 2024
- Part 3: Cleaning Data & Debugging Data Pipelines in 2024
- Part 4: The Web Scraping Landscape & Predictions for 2024
This Year’s Web Scraping Game-Changer: Generative AI and LLMs
In 2023, the adoption of generative AI technologies surged significantly and has only surged more in 2024. According to business research firm Gartner, by 2026, over 80% of enterprises in industries like healthcare, life sciences, legal, financial services, and the public sector will have used or deployed an AI-based application.
The Impact Of AI on Web Scraping Techniques
The unveiling of Large Language Models (LLMs) like GPT-4 has brought on a new era in web scraping, not to mention the internet and the economy as a whole. AI has fundamentally changed how people search for information online, how businesses provide data and information to customers, how information is processed, and of course, how web scraping tools function. Because of this drastic shift, AI has transformed web scraping and the web scraping techniques one needs to be successful through three significant dimensions.
1. Enhanced Parsing and Robustness
LLMs bring a new level of sophistication to web scraping. Moving beyond traditional script-dependant methods, LLMs enable web scraping tools to autonomously adapt to a wide range of data patterns and structures, reducing the need for manual adjustments. For example, AI-powered web scraping tools can automatically recognize and interpret diverse data formats, making it easier to extract relevant information from complex web pages. This adaptability enhances efficiency and accuracy, allowing for more seamless data extraction processes.
2. Dynamic Proxy Integration
AI-driven optimization engines are now integral to web scraping tools. Tools like Nimble API use AI to dynamically select the most effective IP addresses for each request. This capability helps to bypass geo-restrictions and minimize the risk of being flagged as a bot. Dynamic proxy integration also improves success rates by ensuring that scraping operations are distributed across various IP addresses, reducing the likelihood of IP bans and increasing overall scraping efficiency.
3. Synthetic Fingerprint Generation for Anti-bot Evasion
Another significant advancement in web scraping techniques is the creation of synthetic fingerprints using AI and machine learning technologies. Synthetic fingerprints simulate real user behaviors, making it harder for websites to detect and block web scraping activities. This technology is especially useful in navigating sophisticated anti-scraping mechanisms that rely on fingerprinting to identify and restrict automated access.

How AI Benefits Web Scraping
The integration of AI into web scraping techniques, processes, and tools not only optimizes data extraction but expands application scopes and enhances the accuracy of data insights. This innovation in web scraping can be applied across every sector under the sun, from e-commerce to finance.
For more insights on the impact of AI on web scraping techniques, read Part 4: The Web Scraping Landscape & Predictions for 2024.
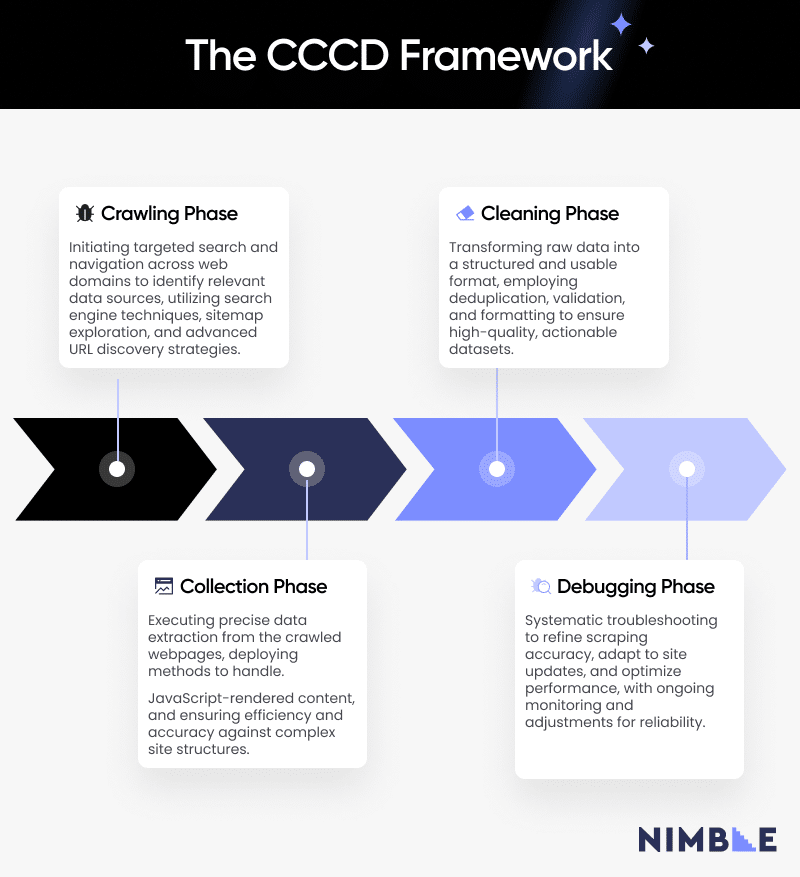
The CCCD Framework: A Modern Approach to Web Scraping
Web scraping techniques have evolved significantly over time. Initially, the application of web scraping was confined to executing simple scripts for content extraction from web pages. However, it has now expanded to include a vast array of tools, companies, and platforms, evolving into a multi-stage procedure. This growing complexity calls for a more structured workflow.
Enter the CCCD framework. This web scraping framework offers a streamlined approach to modern web scraping with an organized, layered workflow that can be used across different web scraping needs. CCCD stands for 4 essential needs in web scraping, which can be addressed step-by-step.
- Crawling
- Collection
- Cleaning
- Debugging
The Benefits of a More Structured Web Scraping Framework and Workflow
The CCCD web scraping framework drastically reduces the learning curve in web scraping and helps businesses understand the web scraping process in its entirety. It also makes web scraping more straightforward, effective, and insightful.
We’ll go over the basics of the CCCD framework briefly here, but if you want to get an in-depth web scraping tutorial using this framework with all the relevant tools, techniques, and tips, you should read:
- Part 2: Crawling and Data Collection in 2024
- Part 3: Cleaning Data & Debugging Data Pipelines in 2024
Phase 1 of the CCCD Web Scraping Framework: Crawling
In the Crawling phase of web scraping, data leaders and teams aim to find the most impactful sources for data extraction, guided by criteria like relevance, accuracy, and technical challenges such as anti-bot systems.
After selecting target sources, the engineering team starts developing strategies to crawl these websites. This involves translating unstructured website data into structured schemas that align with the organization’s needs, a process that combines technical and creative skills.
The crawling methods vary based on the website’s architecture. Single-page applications and traditional server-based sites call for slightly different web scraping techniques. The effectiveness of crawling is evaluated based on how comprehensively your web scraping technique combines effective use of data sources with efficiency, cost, and long-term reliability.
Some of the most common web scraping techniques employed for crawling today include:
Search Engine Utilization
Using search engines like Google to discover URLs is a common starting point. Techniques such as advanced search operators can help locate specific data sources relevant to your needs.
Sitemap Crawling
Websites often have sitemaps that list all accessible URLs. Systematically crawling these sitemaps can provide a comprehensive list of data sources.
Website Search-Based Crawling
Many websites offer internal search functions that can be leveraged to find additional URLs and data points.
URL Formatting
Creating specific URL patterns can help in accessing data efficiently, especially when dealing with paginated or categorized data.
Advanced Web Scraping Tools for Crawling
- Nimble API: Provides advanced crawling capabilities with dynamic proxy and fingerprinting solutions.
- Diffbot: Known for its machine learning-driven automation that can extract data at scale.
- Scrapy: Popular open-source web scraping framework.
- Selenium and Puppeteer: Popular browser automation tools.
- Octoparse: A no-code managed service that makes crawling accessible to beginners.
To learn more crawling tips and tools and to get a web scraping tutorial about the crawling phase, read Part 2: Crawling and Data Collection in 2024
Phase 2 of the CCCD Web Scraping Framework: Collection
In the Collection phase, the focus shifts from identifying web pages to extracting data from them. In general, there are three categories of web scraping techniques and tools that are applied to the collection phase:
- Traditional HTML Scraping: Effective for static content but not suitable for dynamic pages.
- Headless Browsers: Ideal for dynamic content but more resource-intensive.
- Internal APIs: Efficient and reliable for structured data extraction.
Which web scraping tools you use is determined by what kind of content you’re scraping, where you’re scraping it from, and what you’re planning on doing with it. The main web scraping challenges faced in the collection phase include:
Scalability
As the volume of data you’re collecting grows, managing cost, data storage and processing, and scraper maintenance becomes more difficult. For this reason, scalable solutions become essential. Serverless APIs like Nimble can handle large-scale data collection by distributing requests across multiple servers and managing load efficiently.
JavaScript Rendering
Many modern websites use JavaScript to load content dynamically. Headless browsers like Selenium and Puppeteer are crucial for rendering and interacting with such content to ensure complete data extraction, although they can be very resource-intensive to use.
Bot Detection
Websites employ various techniques to detect and block automated requests. These techniques include JavaScript challenges, browser fingerprinting, and TLS fingerprinting. AI-powered tools like Nimble’s Browserless Drivers can help circumvent these measures by mimicking human browsing behaviors and adapting to detection mechanisms.
Advanced Web Scraping Tools for Collection
- Nimble API: An all-in-one solution for data collection that includes advanced anti-bot features like AI fingerprinting. Useful for large-scale data collection.
- Bright Data: A comprehensive web data collection platform with various tools and solutions designed to cater to different data collection needs at scale.
- Zyte: Provides a suite of AI tools and solutions for large-scale data collection.
- Apify: Offers code templates and ready-made scrapers that make data collection easy for beginners.
To learn more collection tips and tools and to get a web scraping tutorial about the collection phase, read Part 2: Crawling and Data Collection in 2024
Phase 3 of the CCCD Web Scraping Framework: Cleaning
The cleaning phase of the CCCD web scraping framework involves parsing and validating data to ensure accuracy and usefulness. This is typically done by structuring scraped HTML data into formats like JSON or CSV and then validating it for consistency and errors.
The cleaning phase is critical for transforming raw data into actionable insights. Here’s a quick breakdown of each step in the cleaning phase:
Parsing
The praising process is about converting raw HTML data into a structured format. It can be done via traditional methods or new AI-powered methods.
Traditional DOM parsing methods are effective for static content, while AI-powered techniques can handle more complex data structures. Combining both approaches can improve data extraction accuracy.
Validation
The validation process ensures data integrity involves checking for consistency, completeness, and correctness. Validation processes help in identifying and rectifying errors, ensuring that the collected data meets quality standards.
Cleaning duplicates is an important part of validation, especially in large data sets. It involves data scraping techniques like hashing and canonicalization.
Looking ahead to 2025 and beyond, AI and statistical methodologies are expected to enhance data integrity testing and validation, further improving the Cleaning phase in this web scraping framework.
Advanced Web Scraping Tools for Cleaning
- Nimble AI Parsing Skills: Combines LLM technology with traditional parsing libraries to dynamically generate self-healing custom parsers for an unlimited number of sources, while operating cost-effectively at scale.
- Beautiful Soup: An open-source Python library for HTML and XML parsing, ideal for static web pages.
- ScrapeStorm: An AI-powered, no-code tool that automatically identifies data structures. Uses a visual, intuitive interface suitable for beginners.
- Scrapy: A popular open-source tool for efficient data extraction from websites.
To learn more tips and tools and to get a web scraping tutorial about the cleaning phase, read Part 3: Cleaning Data & Debugging Data Pipelines in 2024.
Phase 4 of the CCCD Web Scraping Framework: Debugging
The Debugging phase of the CCCD web scraping framework is vital for keeping your web scraping operations efficient, reliable, and up and running. It involves detecting, reporting, and resolving issues that may occur when web scraping.
While many of the web scraping techniques and solutions we have recommended so far are excellent, issues are bound to arise, and comprehensive debugging and monitoring frameworks are needed to minimize data inaccuracy and contamination.
Unlike the other phases, which should be executed in a step-by-step manner, the debugging phase must be applied across all other phases in the framework. Here is a quick summary of how debugging should be applied across the CCCD web scraping framework:
Debugging Workflow: Crawling Phase
- Monitor: HTTP errors, timeouts, and network issues.
- Key Activities: Verifying website relevance, ensuring comprehensive page detection, and managing URLs effectively.
- Common Issue: Mistaking irrelevant websites for relevant ones due to outdated keyword filters.
Debugging Workflow: Collection Phase
- Monitor: Collection operations and the proxy network.
- Key Activities: Detecting anti-bot blocks, testing proxy reliability, ensuring effective IP rotation, and maintaining anonymity and security.
- Common Issue: Encountering access denials due to inadequate IP proxy rotation.
Debugging Workflow: Cleaning Phase
- Monitor: The accuracy and consistency of parsed data.
- Key Activities: Validating data and handling parsing errors.
- Common Issue: Incorrect data parsing due to unexpected changes in HTML structure.
Best Practices: Important Web Scraping Techniques for Debugging
- Automated Testing: Utilize testing frameworks to identify potential issues.
- Logging and Alerting: Implement comprehensive logging and real-time notifications for issues.
- Version Control: Track changes in scraping scripts for easy issue identification and resolution.
- Continuous Monitoring: Use tools to monitor scraping processes, server resources, and data quality.
Advanced Web Scraping Tools for Debugging
- Monte Carlo: For data observability. Helps test, monitor, and maintain data accuracy across your pipelines.
- Great Expectations: Offers both open-source and cloud-based solutions for monitoring and maintaining data quality.
- Integrate.io: A no-code solution for monitoring data pipelines that’s great for beginners. Offers flexible real-time alerting and management of up and downstream data.
- Apache Airflow: For workflow management.
- IBM Rational Software Analyzer: Can detect defects early and optimize performance.
To learn more debugging tips and tools and to get a web scraping tutorial about the debugging phase, read Part 3: Cleaning Data & Debugging Data Pipelines in 2024.
Future Trends and Predictions In Web Scraping Techniques
As we look to the future, the world of web scraping is set to drastically change, mostly due to advancements in generative AI and LLMs. These technologies are expected to enhance every phase of the CCCD web scraping framework and play a crucial role in expanding the capabilities and applications of web scraping.
Here is a quick summary of the biggest trends in web scraping we predict for the rest of 2024 and beyond.
Increased Use of AI for Data Extraction
AI will further streamline data extraction processes, making them more adaptable and efficient.
Enhanced Anti-Detection Techniques
As websites implement more sophisticated anti-scraping measures, web scraping tools will need to evolve to counter these defenses.
Integration with Big Data and Analytics
Web scraping will increasingly integrate with big data platforms and analytics tools, providing more comprehensive and actionable insights.
To learn more about future trends in web scraping and how AI is changing the web scraping techniques you need to succeed, read Part 4: The Web Scraping Landscape & Predictions for 2024.
Conclusion
Web scraping has changed a lot in recent years, and is due to change even more in 2025 and beyond. Although AI has quickly disrupted many of the traditional ways web scraping has been performed, it also offers a massive opportunity to enhance the efficiency and effectiveness of your web scraping techniques.
By leveraging the CCCD framework, using AI-powered tools to your advantage, and following the tips and techniques in this guide, you can scrape more accurate data than ever before.
But, this was just an introduction. If you’d like to take an even deeper dive into how web scraping is changing and how you can implement the CCCD framework to optimize your web scraping techniques, read the next 3 parts of this series:
FAQ
Answers to frequently asked questions
%20(1).png)




.png)

.png)
.avif)